library(idiolect)
#> Loading required package: quanteda
#> Package version: 4.3.1
#> Unicode version: 15.1
#> ICU version: 74.2
#> Parallel computing: disabled
#> See https://quanteda.io for tutorials and examples.idiolect is a package that depends on
quanteda for all the main Natural Language Processing
functions. Although the basic object types and functions are described
in detail in the documentation of this package, familiarity with
quanteda is highly recommended. More information about
quanteda can be found on its website.
Introduction
Authorship Analysis is defined as the task of determining the likelihood that a certain candidate is the author of a certain set of questioned or disputed texts. We call Forensic Authorship Analysis a task of this kind applied in a real forensic case.
In Forensic Linguistics, typically:
- indicates the set of disputed or questioned texts.
- indicates the texts written by the candidate author and collected as comparison material.
We then indicate with the reference dataset that might have to be compiled by the analyst for the specific case (Ishihara et al. 2024).
As an example, the text could be a text committing a crime, such as a threatening letter, or some text that is evidence in an investigation, such as a set of text messages. would then be the set of texts authored by the suspect author of . Finally, would be made up of texts that are comparable to and , for example in genre/register, mode of production, and any other parameter that the linguist maintains as being important for the analysis in the particular case.
A crucial difference between Authorship Analysis and Forensic Authorship Analysis is that whereas the former can be treated as a classification task where the final answer is binary (‘candidate is the author’ vs. ‘candidate is NOT the author’), the latter needs an expression of likelihood for the two competing propositions or hypotheses, the Prosecution Hypothesis vs. the Defence Hypothesis , for example:
: The author of and the author of are two different individuals.
The job of the forensic linguist in a forensic context is to analyse the linguistic evidence and determine which hypothesis it supports and with what degree of strength, thus aiding the trier-of-fact in reaching a conclusion. The role of the forensic linguist is therefore not to provide a YES/NO answer but rather to express the strength of the evidence in favour of each of these two hypotheses.
Given , and , the workflow for this analysis involves four steps:
- Preparation: This step involves any pre-processing step that is necessary for the analysis with the chosen method.
-
Validation: Carry out an analysis on the case data
or on a separate dataset that has been designed to be similar to the
case material in order to validate that the chosen method works for this
particular case. Even though all the methods contained in
idiolecthave been tested in various published academic studies, it is also important that the methods are tested (i.e. validated) for any specific case (Ishihara et al. 2024). - Analysis: Carry out the analysis on the real , , and .
- Calibration: Turn the output of (3) into a Likelihood Ratio that expresses the strength of the evidence given the two competing hypotheses.
Preparation
The input for the key functions of idiolect is a
quanteda corpus object with two docvars:
author, containing the unique names of the authors of each
text, and textname, the name of each text. Users can create
this corpus using quanteda. For guidance on how to create a
corpus with quanteda see this page.
However, for users who are less experienced with
quanteda, idiolect has a convenience function
called create_corpus() to import texts in this format
starting from a folder of plain texts. This function is simply calling
readtext (therefore this package must be installed) while
scanning the name of the files for the metadata of each text,
specifically the name of the author and the name of the file. The syntax
to follow to name the files is:
Assuming that a folder of plain text files with names according to
this syntax are ready on the user’s computer, then the following command
(not executed here) loads the folder as a quanteda corpus
object containing the required docvars.
corpus <- create_corpus("path/to/folder")In this vignette, instead, the rest of the workflow is demonstrated
using a small dataset of the Enron corpus that is included in this
package (see ?enron.sample).
corpus <- enron.sampleThis corpus is a quanteda corpus object that contains
ten authors with approximately the same amount of data.
Content masking
A highly recommended and sometimes necessary pre-processing step is content masking. This step consists in masking or removing words or other tokens in the text that are likely to create noise for an authorship analysis. Hiding content not only avoids incorrectly attributing a text based on the correlation between topics and authors (Bischoff et al. 2020) but also tends to improve the performance of authorship analysis methods in cross-topic and cross-genre situations (Stamatatos 2017).
Three content masking methods are implemented in
idiolect: (1) the POSnoise algorithm developed by
Halvani and Graner (2021); (2) the
frame n-grams approach introduced by Nini (2023); and (3) an implementation of the
TextDistortion approach originally introduced by Stamatatos (2017). These options are available
in the contentmask() function. Because this function
depends on spacyr
and this requires downloading a parsing model for a language for the
automatic tagging of Parts of Speech (e.g. nouns, adjectives, adverbs),
this function is not run in this vignette. Instead, the Enron sample has
already been content-masked using POSnoise, as can be seen from
the preview of the corpus
corpus
#> Corpus consisting of 49 documents and 2 docvars.
#> Kevin_h_Mail_1 :
#> "N N N N wants to be N when he V up likes N P , N for doing t..."
#>
#> Kevin_h_Mail_3 :
#> "i 've V a J one , but the only N N N i have is on a N N from..."
#>
#> Kevin_h_Mail_4 :
#> "this was J towards the N of a J N N N . in N , P P helped th..."
#>
#> Kevin_h_Mail_5 :
#> "V the N for more than D N may get you V . a N N with a N and..."
#>
#> Kevin_h_Mail_2 :
#> "P , here 's the J N on our P P N V to V the V needs of the P..."
#>
#> Kimberly_w_Mail_3 :
#> "they also have J N at the J N of P D per N and only a D J ea..."
#>
#> [ reached max_ndoc ... 43 more documents ]The POSnoise algorithm essentially replaces all words that tend to contain meaning (nouns, verbs, adjectives, adverbs) with their Part of Speech tag (N, V, J, B) while all the other words or tokens are left unchanged. In addition to this operation, POSnoise contains a white list of content words that mostly tend to be functional in English, such as verbs like do, have, make or adverbs such as consequently, therefore.
The following code should be used to run the
contentmask() function. This will require installing and
initiating a spacy parsing model
for the language chosen. This process should happen automatically.
posnoised.corpus <- contentmask(corpus, model = "en_core_web_sm", algorithm = "POSnoise")If the installation did not start automatically, then the
installation of the spacyr package and of the default model
can be done as follows:
install.packages("spacyr")
spacyr::install_spacy()Data labelling
In this example it is simulated that Kimberly_w_Mail_3, written by the author Kimberly_w, is the real text and all the other known texts written by Kimberly_w are therefore the set of known texts . The remaining texts from the other authors are the reference samples .
Q <- corpus_subset(corpus, author == "Kimberly_w" & textname == "Mail_3")
K <- corpus_subset(corpus, author == "Kimberly_w" & textname != "Mail_3")
R <- corpus_subset(corpus, author != "Kimberly_w")Vectorisation
Before applying certain authorship analysis methods, each text or
sample must be turned into a numerical representation called a
feature vector, a process typically referred to as
vectorisation. idiolect has a function to
vectorise a corpus called vectorize(). The features
normally used by many authorship analysis methods are
-grams
of words and punctuation marks or characters. For example, the
text can be vectorised into the relative frequencies of its words using
this code.
vectorize(Q, tokens = "word", remove_punct = FALSE, remove_symbols = TRUE, remove_numbers = TRUE,
lowercase = TRUE, n = 1, weighting = "rel", trim = FALSE) |>
print(max_nfeat = 3)
#> Document-feature matrix of: 1 document, 136 features (0.00% sparse) and 2 docvars.
#> features
#> docs they also have
#> Kimberly_w_Mail_3 0.00289296 0.009643202 0.0192864
#> [ reached max_nfeat ... 133 more features ]or, as the most frequent 1000 character 4-grams relative frequencies, for example, using
vectorize(Q, tokens = "character", remove_punct = FALSE, remove_symbols = TRUE, remove_numbers = TRUE,
lowercase = TRUE, n = 4, weighting = "rel", trim = TRUE, threshold = 1000) |>
print(max_nfeat = 3)
#> Document-feature matrix of: 1 document, 1,094 features (0.00% sparse) and 2 docvars.
#> features
#> docs they hey ey a
#> Kimberly_w_Mail_3 0.0009771987 0.0009771987 0.0003257329
#> [ reached max_nfeat ... 1,091 more features ]The output of the function is a quanteda
document-feature matrix (or dfm) that can efficiently
store even very large matrices.
This vectorize() function is mostly designed for expert
users because different choices in the parameters of the vectorisation
can be made using each single authorship analysis method function. In
addition, since most authorship analysis methods already have a default
setting of these parameters, these are already the default for the
authorship analysis functions.
This step is therefore not necessary unless there are specific requirements, as any vectorisation is handled by the functions that apply the authorship analysis methods.
Validation
The first step of the validation is to remove the real text. This is the actual forensic sample to analyse and it must be therefore removed when validating the analysis. The validation set is therefore made up of only the and datasets
validation <- K + RThis dataset must now be re-divided into ‘fake’ texts and ‘fake’ texts.
To create two new disjoint datasets, validation.Q and
validation.K, we randomly sample one text for each author
to be the ‘fake’
and we leave the rest to be their ‘fake’
texts.
validation.Q <- corpus_sample(validation, size = 1, by = author)
validation.K <- corpus_subset(validation, !docnames(validation) %in% docnames(validation.Q))This is not the only way in which a validation analysis can be conducted. A completely different dataset that is similar to the case data could be used, for example. This simpler approach is more suitable for this small example.
Authorship analysis
In this example, the scenario simulated is a verification: was the unknown text written by the author, Kimberly_w? For this reason, the method chosen is one of the most successful authorship verification methods available at present, the Impostors Method (Koppel and Winter 2014), and in particular one of its latest variants called the Ranking-Based Impostors Method (Potha and Stamatatos 2017, 2020).
This analysis can be run in idiolect using the function
impostors() and then selecting the default parameter for
the algorithm argument, “RBI”. The main argument of
this function are the q.data, which is the set of
texts to test, and the k.data, which is the set of
texts from one or more authors that are going to be tested, and finally
the set of impostors data, cand.imps. For this example, the
impostors data is
set but generally the recommendation is to use another dataset when
possible.
The impostors() function accepts more than one author in
k.data and it also accepts the same dataset as input for both
k.data and cand.imps. When the same dataset is used,
impostors() will test each author in k.data and
use the texts written by other authors as impostors.
In contrast to other authorship analysis functions like
delta() and ngram_tracing(),
impostors() does not offer additional parameters to modify
the vectorisation process because all the Impostors Method algorithms
already have a well-specified default setting. If the user wants to
change these they should then vectorise the corpus separately using
vectorize() and then use the dfm as the input of
impostors().
The RBI variant of the method requires setting a parameter called , which is the number of most similar impostors texts to sample from the wider set of impostors. The recommended setting is or but for simplicity this is set to in this example. This is not a realistic setting and it is used here only as an example.
Because an analysis using the Impostors Method can have long run times, this function can also be parallelised using more than one core.
res <- impostors(validation.Q, validation.K, validation.K, algorithm = "RBI", k = 10)The output of impostors() is a data frame showing the
results of comparing each
author with each
text. The variable target is TRUE if the comparison is a
same-author one or FALSE if it is a different-author one. The variable
score contains the Impostors score, which is a value that
ranges from 0 to 1. Other authorship analysis functions return the same
data frame type with the same columns. The variable score
therefore represents different quantities depending on the analysis
function used (e.g. for delta(), this is the
coefficient, and so on).
res[1:10,]
#> K Q target score
#> 1 Kimberly_w Kevin_h_Mail_1 FALSE 0.750
#> 2 Kimberly_w Kimberly_w_Mail_5 TRUE 1.000
#> 3 Kimberly_w Larry_c_Mail_2 FALSE 0.500
#> 4 Kimberly_w Lindy_d_Mail_3 FALSE 0.833
#> 5 Kimberly_w Liz_t_Mail_4 FALSE 0.667
#> 6 Kimberly_w Louise_k_Mail_2 FALSE 0.667
#> 7 Kimberly_w Lynn_b_Mail_3 FALSE 1.000
#> 8 Kimberly_w Lysa_a_Mail_5 FALSE 0.500
#> 9 Kimberly_w M_f_Mail_3 FALSE 0.750
#> 10 Kimberly_w M_l_Mail_2 FALSE 0.833In order to assess the results of this validation analysis, the
function performance() can be used to return a series of
performance metrics. This function can take one or two result data
frames as input. If two are provided, then one is used as training and
the other one as test. If only one data frame is provided, then the
performance metrics are calculated using a leave-one-out approach.
The procedure followed by this function is to held out one text (if
leave-one-out, otherwise the test dataset in its entirety) and then use
the rest of the data (or the training dataset) as a calibration dataset
to calculate a Log-Likelihood Ratio
().
This analysis is done using the calibrate_LLR() function,
which fits a logistic regression model to calibrate the score into a
log-likelihood ratio Ishihara (2021) using
the ROC library (Leeuwen
2015).
The output of the function is the following:
p <- performance(res, progress = FALSE)
p$evaluation
#> Cllr Cllr_min EER Mean TRUE LLR10 Mean FALSE LLR10 TRUE cases
#> 1 0.7620334 0.7183427 26.26582 0.4062006 -0.4368895 10
#> FALSE cases AUC Balanced Accuracy Precision Recall F1 TP FN FP
#> 1 90 0.7766667 0.7666667 0.25 0.8 0.3809524 8 2 24
#> TN
#> 1 66The and coefficients are used to evaluate the performance of the system (Ramos et al. 2013). These coefficients estimate the accuracy of the , where a value of 1 indicates chance-level accuracy and a lower coefficient suggests that there is valuable information in the results, with lower values of suggesting better performance. The other binary classification metrics returned, such as Precision, Recall, and F1, are all calculated using as the threshold for a TRUE (or same-author in this case) classification.
In the present example, a 0.762 suggests that the performance is acceptable to be able to proceed with the actual forensic analysis. The , which is the component of measuring the amount of discrimination, is even lower, which means that there is a substantial difference in the two distributions. This is confirmed by the Area Under the Curve value of 0.777. Because of the large disparity between the TRUE and FALSE test cases, the values of Precision and F1 are misleading. The Balanced Accuracy value of 0.767, however, again suggests a substantial amount of discrimination at .
The results of the analysis can also be plotted using a density plot
for each of the two distributions, TRUE and FALSE. This can be done
using the density_plot() function
density_plot(res)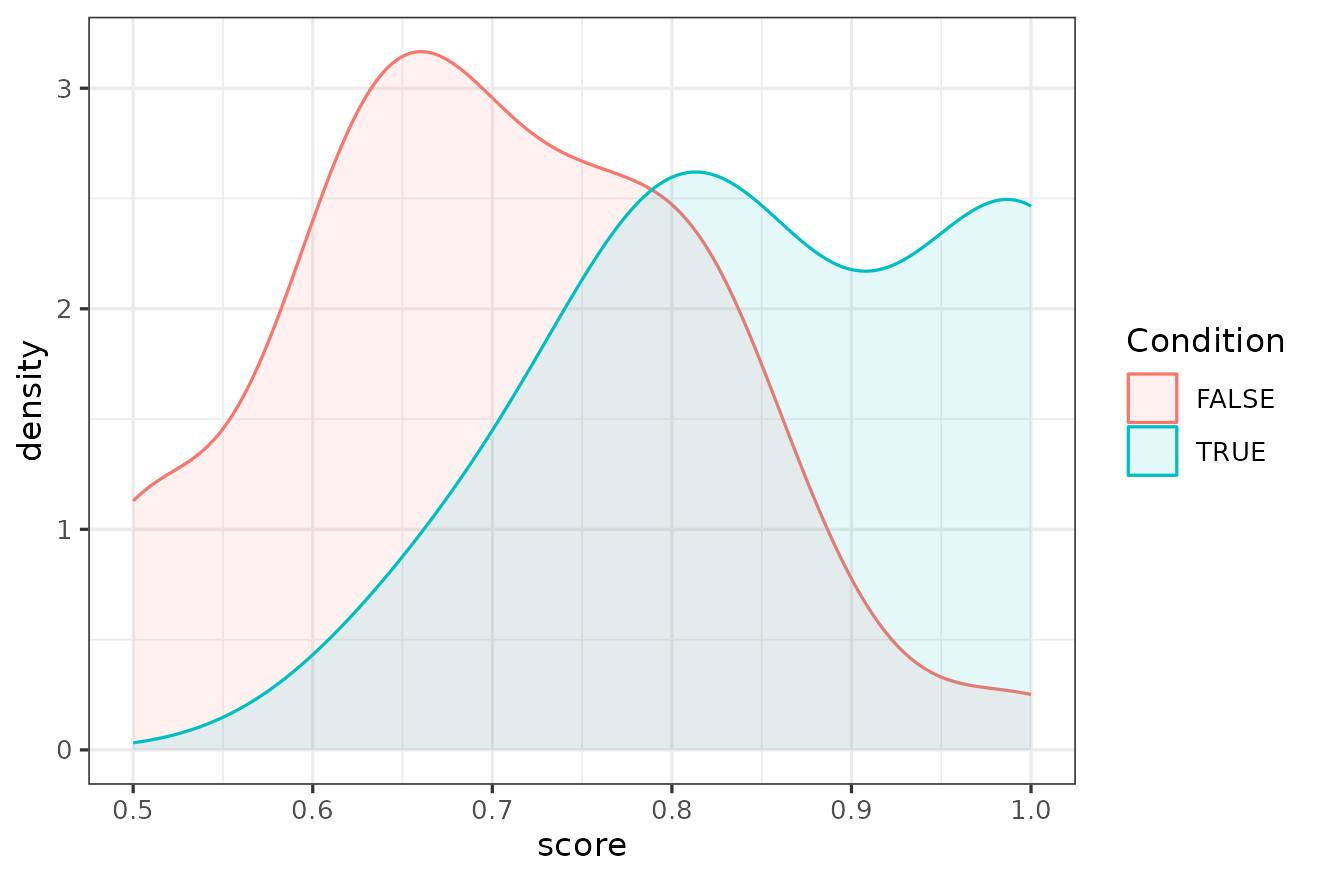
This plot shows the values of the score on the horizontal axis and the density for TRUE (blue) vs. FALSE (red) on the vertical axis.
These findings are evidence that the method is validated for this dataset and it is now possible to analyse the text and use these results to calibrate the for .
Analysis of
At this point the only thing left to do is to analyse the forensic
data by feeding the real
,
,
and
into the impostors() function using the same settings used
for the validation.
q.res <- impostors(Q, K, R, algorithm = "RBI", k = 10)Because there is only one text, the final table of results only contains one row
q.res
#> K Q target score
#> 1 Kimberly_w Kimberly_w_Mail_3 TRUE 1Qualitative examination of evidence
Before reaching the conclusions, it is often important to inspect the features that the algorithm has considered for the analysis. In a forensic analysis, good knowledge of the data is important and best practice require the analyst to be very familiar with the dataset before running a computational analysis. Reading the data and being familiar with it can lead to the addition of more pre-processing steps to remove noise and can help the analyst spot any problem mistakenly introduced by the algorithm.
In addition to familiarise themselves with the data,
idiolect allows the analyst to explore the most important
feature considered by the authorship analysis method used. For example,
when using the RBI algorithm with impostors() then the
parameter features can be switched to TRUE to obtain a list of
important features. Running this again with this parameter switched on
produces the following results
q.res2 <- impostors(Q, K, R, algorithm = "RBI", k = 10, features = TRUE)
strwrap(q.res2$features, width = 70)
#> [1] "to me|o me |, her| P on|P on |re al|ve no|i jus|lso ,|so , |P P f|N N"
#> [2] ".|also |ll me|l me | also| N i |e N s| few |you n|ou ne|u nee|our"
#> [3] "J|ur J |ust w|st wa|few N|ew N |P P V|ve a | him |as i | , he|u"
#> [4] "and|the J|he J |V J N|u hav|, i w|P P i|N N N|P P o|, N a|do no|o"
#> [5] "not|P D .|you h|ou ha| too |re is|s for|r N o| P in|P in |our P|ur P"
#> [6] "| P fo|P for| may | at t|e a N|o V i| P to|P to |o be |lso V|so V"
#> [7] "|thing|hing |V it |is J |r N w|P , h|nd th|ou an|to do|o do | two |"
#> [8] "we w| do n|rom P|om P | N fr|ave n|e N w| here|t is |but i|, i h|"
#> [9] "into|into | we V| yet |you N|ou N |ke a | V it|ave a|ng th|s N N|n P"
#> [10] ",| our |s you|N fro|ere i|N who|me N | see | N or|N or |is V | can |"
#> [11] "we '|ut i | V wi|V wit|P , w|V our|N for| but |an V | one |ome N| N"
#> [12] "fo|ave b|or V |other| to m| is o| a N | J N |e hav|J N o|e tha|"
#> [13] "look|i am | , bu|, but|eithe|ither|P P .|t wan|can V|t to |in P |in V"
#> [14] "|to se| N J |ore N| get |N in |N , N| as i| in P|e is |ith y|th yo|h"
#> [15] "you|e J N|ve V | , th|n N .| i ha|some | is J|are a|e an |i hav|"
#> [16] "othe|this | a J |a N N|my N | is a| J fo|J for|e thi|n our|s the|may"
#> [17] "b|ay be|y be |ase l|se le|e let|o see|did n|o hav| V ou| it .|"
#> [18] "some|or P | N on| P 's|P 's | is V| so i|d the|d you| , i |e P P|n"
#> [19] "you|if yo| you |is a |the N|he N | B , |P , P|t V a|and t| this|N on"
#> [20] "|a N t|V tha|want |in a |e wil|a N f| , so|ther |we ar| have|i wil|"
#> [21] "my N|have | P N |o V o| V J |hat P|r N a|t the|a J N| V an| 's N|'s N"
#> [22] "|P P P| the | N if|N if | P is|at i | work| on P|on P |with |N , b|N"
#> [23] "has|a N a|ant t|nt to|ow if|w if |V and|ake a| in a|e of | are |is N"
#> [24] "|as V | week|week | J in|J in | N of|N of |e V i|V to |or N |, we |to"
#> [25] "be| to b|N N o|e you| V to| V my|V my |r J N| V fo|V for|you t|V thi|"
#> [26] "to s| know|e N N|V in |f you| , wh| V a |me to| N in|t kno|u to |ed"
#> [27] "to|his N|P P N|fter | me t| star|start|the P|he P |know |for t|out w|"
#> [28] "'ll | N th| was |now i|N V N| afte|P , a|r N i|ere w|ach o|ch of|h of"
#> [29] "|o J N|i 'll|after|r D N|ill h| it t|ether|e als|P tha|o V .|"
#> [30] "only|nning|ning |y N N|e V y|ou to| out |se V |ase V|J N ,| just|"
#> [31] "each|each |ill V|t you|eek .|are V|look |o mak|only |ou wo| P D |l"
#> [32] "hav|worki|orkin|rking|to ma|at yo|tart | N P |our N|ur N | both|both"
#> [33] "|e in | of N|of N |J N .|V you| give|N N a|and g|just |at P |o the|t"
#> [34] "V i|e and|s to | in t|here |V any|o V y| by N|ll V |o you| , as|, as"
#> [35] "|N we |e J t|in th| , we|n the|needs|eeds |ll ha|for N|hat y| N we|re"
#> [36] "V |N N ,|N N i|your |s N ,|is th|ve an|by th| V yo| , yo|,"
#> [37] "you|pleas|lease|ease |re J | call|e nee|y N .| and |make |P is |N"
#> [38] "tha|ough |by N | if y|t i w|s tha|V a N| is t|o V u| me a|her N|you"
#> [39] "a|e V a|call |V the| any |er N | be V|be V |e wou|or th| plea| she"
#> [40] "|at we|more |P P a| P th| J , |or D |we ne|e to | P , | we n|ing o|t"
#> [41] "thi| V in| that|r P P|we wo| N an|e N .|N and|o V N| J to|J to | P V"
#> [42] "|d to | V N |ch N | has | did | V on|hat i|V P P|r our| N by|N by |th"
#> [43] "N | a fe|a few|V N o| a D |d lik|e V f|i wou|hat h|ke to|ill n|"
#> [44] "find|find |ld li|uld l| per | let |N , s|N , h|ike t|ve be|e bee|for"
#> [45] "h|y hav|s N w| woul|would| like|like |e if | be J|be J |ith P|th P"
#> [46] "|in N |e V t| P ha|give |ow wh|ee if|you m|and i|o V t| to V|to V |"
#> [47] "on t| with|ted t|or yo| , pl|, ple|P and|at th| make|for y|t me |now"
#> [48] "w|not V|and h| P an|o P P|let m|et me| me k|me kn|e kno|ith N| V up|V"
#> [49] "up | i am| in N|any N|ny N |J N N| will|ot V |d P P| i V | , P |r N"
#> [50] ".|f the|ould |eed t| N wi|nd i | for |ome o|me of|t wit|f N .|o V w|"
#> [51] "N so|N so |m to |ne of|e V .|king | them|them |one o|to ta|n to |we"
#> [52] "ha| your|id no|see i|hat N|e J .|ave V| N B |nd N |o V a| of y|of"
#> [53] "yo|and N| N N | what| to t|to ge|o get|a N o| if t|e V N| we h| V"
#> [54] "th|i nee|if we|f we |oing |r the| from| had | N , |d not|e N o|u V t|"
#> [55] "want|need |from | , N |N V t"The RBI method uses as features character 4-grams and a list of these
features is clearly hard to interpret by a human analyst. Despite the
complexity, this is not an impossible task. idiolect offers
a function to aid exploration called concordance(), which
uses quanteda’s kwic() as its engine.
concordance() takes as input a string representing one
or more words (or punctuation marks). For example, one of the most
important character 4-gram seems to be <, her> so this
could be the search target.
concordance(Q, K, R, search = ", her", token.type = "character") |>
dplyr::select(pre, node, post, authorship)
#> pre node post authorship
#> 1 . P , her e is Q
#> 2 we V , her e is Q
#> 3 . P , her e is Q
#> 4 ur N , her e is K
#> 5 . P , her e is K
#> 6 . P , her e is K
#> 7 nd P , her e is K
#> 8 . P , her e is K
#> 9 N N , her e is K
#> 10 st P , her e is K
#> 11 N N , her e is K
#> 12 P , her e 's Reference
#> 13 P P , her e out Reference
#> 14 nd P , her e is Reference
#> 15 . P , her e are Reference
#> 16 . P , her e are ReferenceThe search reveals that this character sequence is a strong characteristic of the candidate author’s writing. However, the real underlying pattern is not the use of a comma followed by the possessive determiner her but the token sequence [, here is], which is only used by the candidate author and one other author in the reference corpus.
concordance(Q, K, R, search = ", here is", token.type = "word") |>
dplyr::select(pre, node, post, authorship)
#> pre node post authorship
#> 1 each of you . P , here is the P P P on Q
#> 2 on this N we V , here is a N N of both Q
#> 3 N for P . P , here is the P P P P Q
#> 4 all . per your N , here is some J N on P K
#> 5 B and V . P , here is the J N N on K
#> 6 N V N . P , here is the P P P P K
#> 7 N . P and P , here is the J for the P K
#> 8 N N yet . P , here is the P P P P K
#> 9 out of the N N , here is the beginning of the N K
#> 10 N on this past P , here is the N we talked about K
#> 11 as per our N N , here is the V P P P K
#> 12 know . P and P , here is a N of N in ReferenceAnother important feature is represented by the two character 4-grams, <lso ,> and <so , >, which are likely to refer to the token sequence [also ,].
concordance(Q, K, R, search = "lso ,", token.type = "character") |>
dplyr::select(pre, node, post, authorship)
#> pre node post authorship
#> 1 N ? a lso , ther Q
#> 2 V . a lso , i ha Q
#> 3 P . a lso , plea Q
#> 4 k . a lso , P ha Q
#> 5 N . a lso , P P K
#> 6 N . a lso , at t K
#> 7 N ? a lso , i 'v K
#> 8 s . a lso , let K
#> 9 a lso , V th K
#> 10 N . a lso , i V K
#> 11 N . a lso , woul Reference
#> 12 . P a lso , V to Reference
#> 13 N . a lso , any Reference
#> 14 N . a lso , have Reference
#> 15 P . a lso , P P Reference
#> 16 N . a lso , you Reference
#> 17 D . a lso , to V Reference
#> 18 N . a lso , tell Reference
#> 19 J . a lso , coul Reference
#> 20 N . a lso , we n Reference
#> 21 J . a lso , ther ReferenceThis is correct and it is referring to the use of also at the beginning of a sentence and immediately followed by a comma.
Although searching all the features returned is clearly a significant
amount of work, by inspecting the list of features carefully and by
using concordance() to explore the features in the data the
analyst can spot patterns or mistakes in the analysis (Ypma, Ramos, and Meuwly 2023).
Conclusions
Although the score assigned to is high, depending on the calibration data, it can correspond to various magnitudes of the .
The
value for
can also be plotted onto the TRUE vs. FALSE distributions using the
second argument of density_plot(). The q argument
can be used to draw a black vertical line that crosses the two
distributions at the horizontal axis corresponding to the score of
.
density_plot(res, q = q.res$score)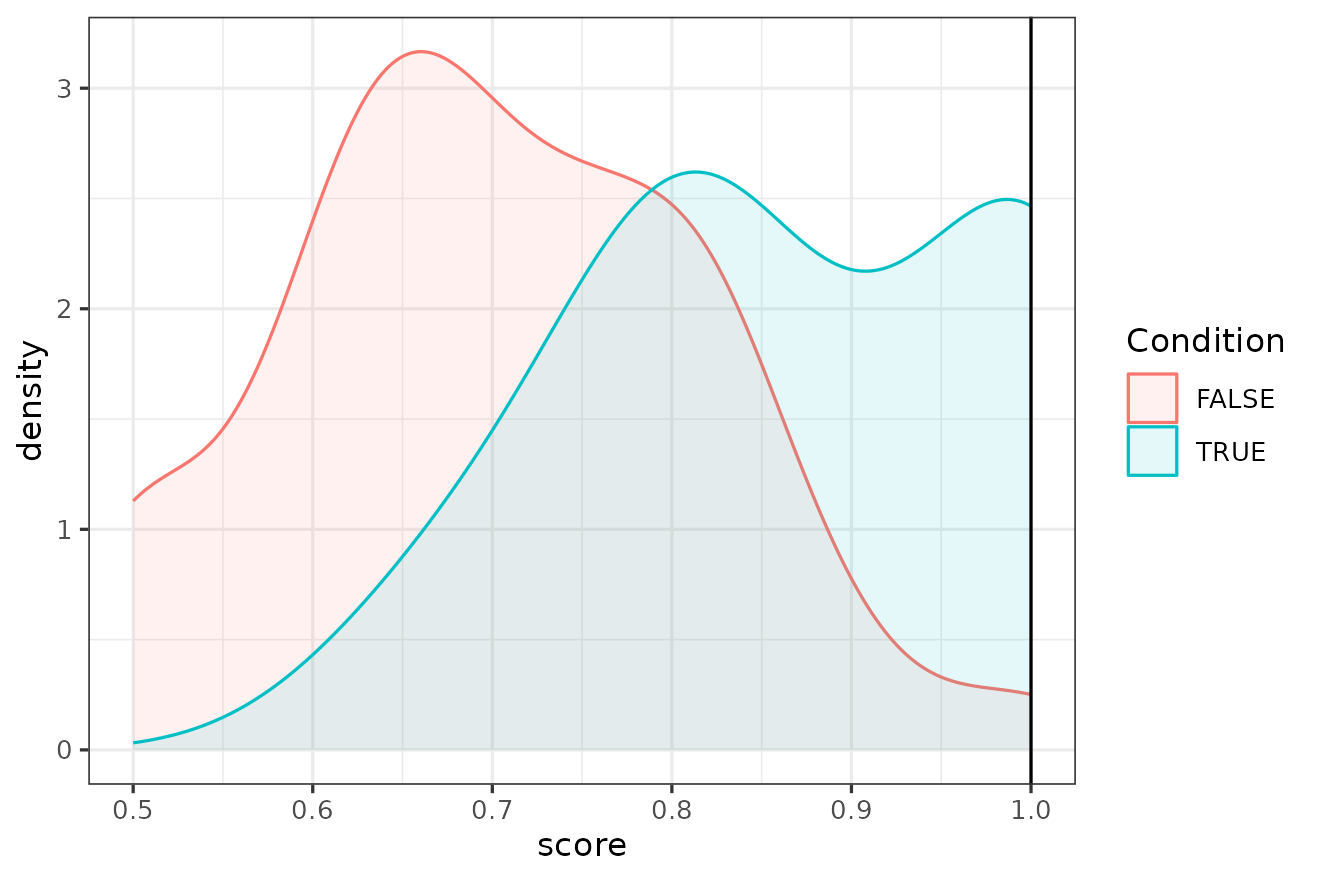
To perform this calibration the calibrate_LLR() function
is used again by using the validation results as calibration data
q.llr <- calibrate_LLR(res, q.res, latex = T)
q.llr$`Verbal label`
#> [1] "Moderate support for $H_p$"
strwrap(q.llr$Interpretation)
#> [1] "The similarity is 13.24 times more likely to be observed in the case of"
#> [2] "$H_p$ than in the case of $H_d$"This function not only returns the value but also the verbal labels and their interpretation (Marquis et al. 2016).
The final conclusion of the analysis is therefore the following:
The similarity score of given is 1, which corresponds to 1.122. The similarity is 13.24 times more likely to be observed in the case of than in the case of . Therefore, the linguistic analysis offers Moderate support for .
This conclusion can be complemented with an explanation of the
implication of these results for the trier of facts by showing a table
of posterior probabilities assuming a range of prior probabilities. This
can be done with the posterior() function by inserting as
input the value of the
posterior(q.llr$LLR) |>
dplyr::select(prosecution_prior_probs, prosecution_post_probs)
#> # A tibble: 11 × 2
#> prosecution_prior_probs prosecution_post_probs
#> <dbl> <dbl>
#> 1 0.000001 0.0000132
#> 2 0.01 0.118
#> 3 0.1 0.595
#> 4 0.2 0.768
#> 5 0.3 0.850
#> 6 0.4 0.898
#> 7 0.5 0.930
#> 8 0.6 0.952
#> 9 0.7 0.969
#> 10 0.8 0.981
#> 11 0.9 0.992The table above reveals that, assuming a prior probability for of 0.00001 (roughly, one out of the population of Manchester), then this would transform this probability to a posterior probability for of 0.000013. In other words, it would not make much substantial difference for the trial.
However, if the prior probability of was 0.5, then these results would turn it to 0.93, which is a substantial change.
The table shows that the present evidence could change the probability that is true to equal or higher than 0.9 only with a prior greater than 0.4.
Acknowledgements
I would like to thank Shunichi Ishihara and Marie Bojsen-Møller for helpful comments on the first draft of this vignette.